
Speech2Text With Sentence Similarity
Understanding speech has always been a tough task, so as to convert it to text. But the scenario has changed a lot. With the advent of Deep Learning, the process has become not only easier but also the accuracy it achieves in understanding and transcribing it to text is really remarkable. In this article I will share how I built a web app that replies to a few questions you asked about me.
One fine evening, I decided to make something that replies when somebody asks about me, on behalf of me. I wanted to make use of some state-of-the-art models for better and powerful performance. So I landed to HuggingFace model Hub. I decided to use Wav2Vec2 for speech recognition, Sentence-transfomers for embedding the sentence, and deploy it in Gradio App to make the inference quick and easy.
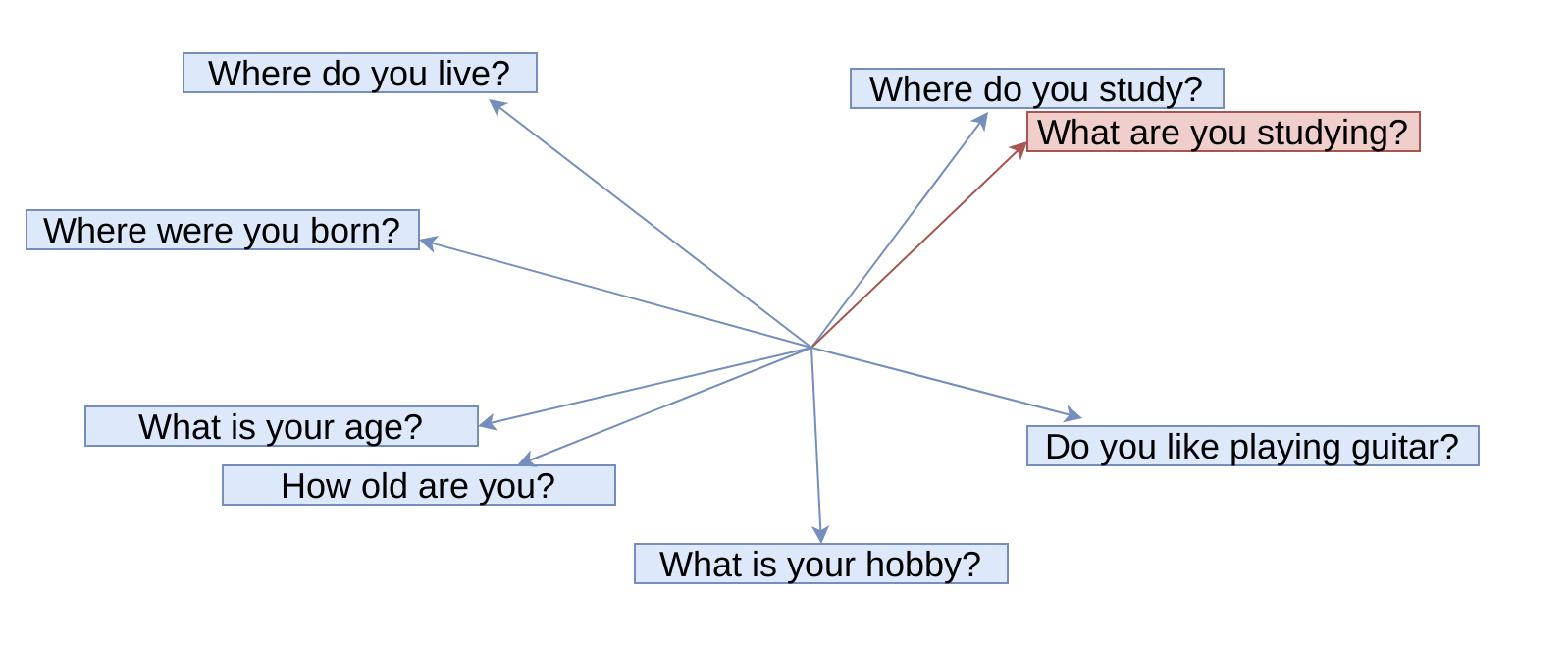 Embedding for Sentences(Blue indicates the existing embedding, red is the embedding for asked question)
Embedding for Sentences(Blue indicates the existing embedding, red is the embedding for asked question)
Initially, I collected a few Questions-Answers pairs that could be asked. I embedded them using the sentence-transformers and stored the embedding. Now, when an audio file is passed to the wav2vec2, it transcribes it. The transcribed text is then embedded using the sentence-transformers. The answer corresponding to the nearest question embedding is then returned (in the case above answer to ‘Where do you study?’).
Lets now dive into the Code Section. The code is pretty easy. You first need to install few libraries.
$ pip install transformers, sentence-transformers, gradio
After installing the libraries, lets write a script to load the models we want.
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from sentence_transformers import SentenceTransformer
def load_wav_model():
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
return model, processor
def load_sentence_model():
return SentenceTransformer('sentence-transformers/paraphrase-xlm-r-multilingual-v1')
Now, we create a utility script that contains function to parse the audio file. It also contains Question-Answer pairing.
import torch
import librosa
QA = {
0: "My brother name is Sanup.",
1: "I live in Kathmandu.",
2: "I like programming and playing guitar.",
3: "I have 4 members in my family.",
4: "I am currently pursuing my bachelors in Computer engineering in Kathmandu University."
}
context_sentence = ["What is your brother name?",
"Where do you live?",
"What is your hobby?",
"How many members are there in your family?",
"What are you studying?"]
def parse_wav_transcription(wav_file, model, processor):
audio_input, sample_rate = librosa.load(wav_file, sr=16000)
input_values = processor(audio_input, sampling_rate=16000, return_tensors="pt").input_values
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.decode(predicted_ids[0])
return transcription
Let’s create a gradio app now to make inferences of our work. Gradio is an absolutely easy yet powerful library to make inferences of your ML models, so if you are feeling hard to make a quick demo of your models, I highly recommend you to check Gradio. With afew lines of code shown below, our project is live.
import gradio as gr
import numpy as np
from models import load_sentence_model, load_wav_model
from utils import QA, parse_wav_transcription
from sentence_transformers.util import cos_sim
wav_model, wav_processor = load_wav_model()
sentence_model = load_sentence_model()
encoded_sentence = np.load('embeddings.npy') # loading the stored embeddings for sample questions
def knowMe(audio):
recorded_sentence = parse_wav_transcription(audio.name, wav_model, wav_processor)
recorded_enc = sentence_model.encode(recorded_sentence) # Embedding the asked question
cosine_sim = [cos_sim(recorded_enc, context_enc) for context_enc in encoded_sentence]
idx = np.argmax(cosine_sim)
return QA[idx]
iface = gr.Interface(fn=knowMe,
inputs = gr.inputs.Audio(source="microphone", type="file", label="Audio"),
outputs=gr.outputs.Textbox(),
title="Know Me - WSG",
description="Ask to Know",
allow_flagging=False
)
iface.launch()
If you want to see demo video of this project, kindly visit to the link below where i have code and embeddings for few questions. And please Star the project if you like the idea.


Comments