
Machine Learning Model in Flask — Simple and Easy
If you have created a machine learning(ML) model and you want your friends to try it out, the best way to do is to deploy your model in a flask server. Flask comes way too handy for beginners who wants to work in deployment of ML model. Flask is a micro web framework written on python. In this article, we will see how to create an ML model to predict Indian Premier League(IPL) first inning score and deploy it in Flask. If you want to view the app, please click here.
Creating Model:
Our first task is to create model. The data set used for training this model is available in kaggle. The data includes every IPL match statistics from 2008–2017. So, lets load the data set:
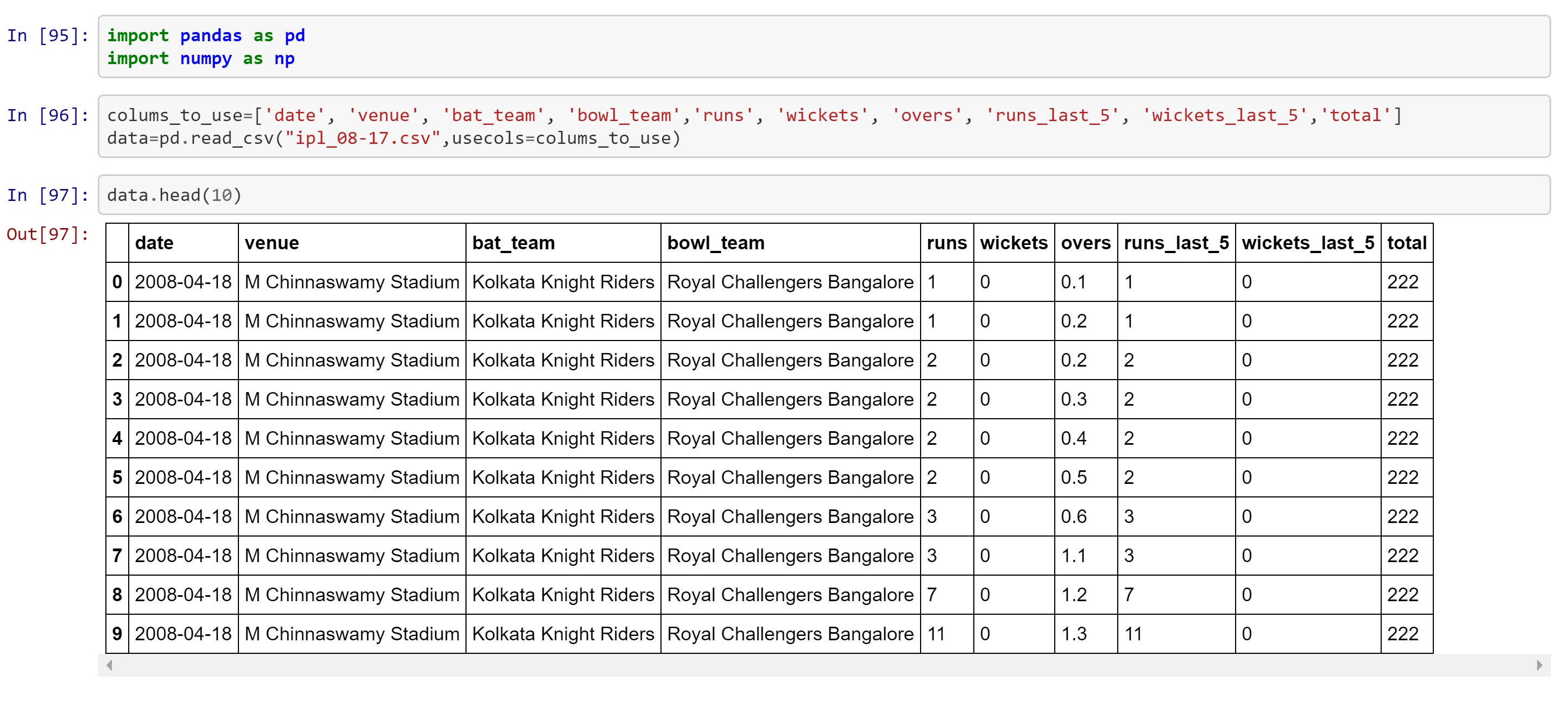
Since our data is from 2008, it includes teams that are not playing in current IPL. So lets remove those data. I have made a list of present teams in IPL, and created a new data frame which has batting and bowling team present in the created team list.
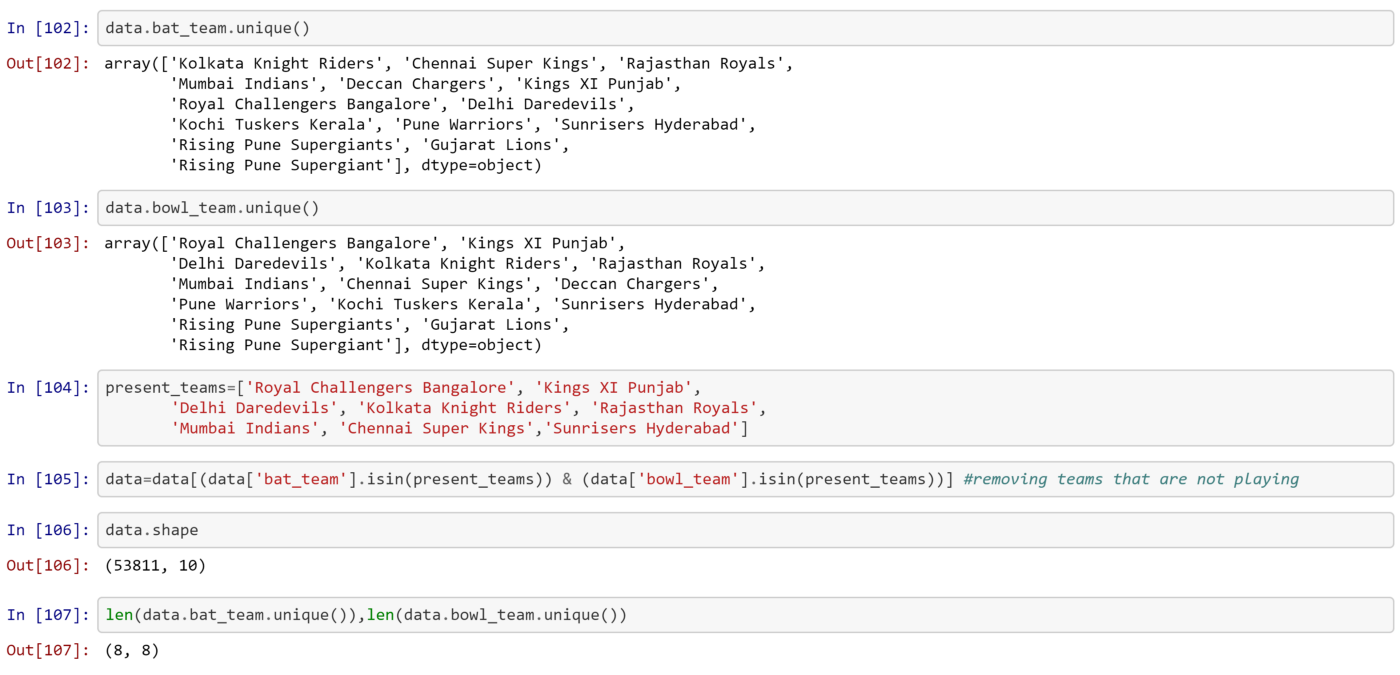
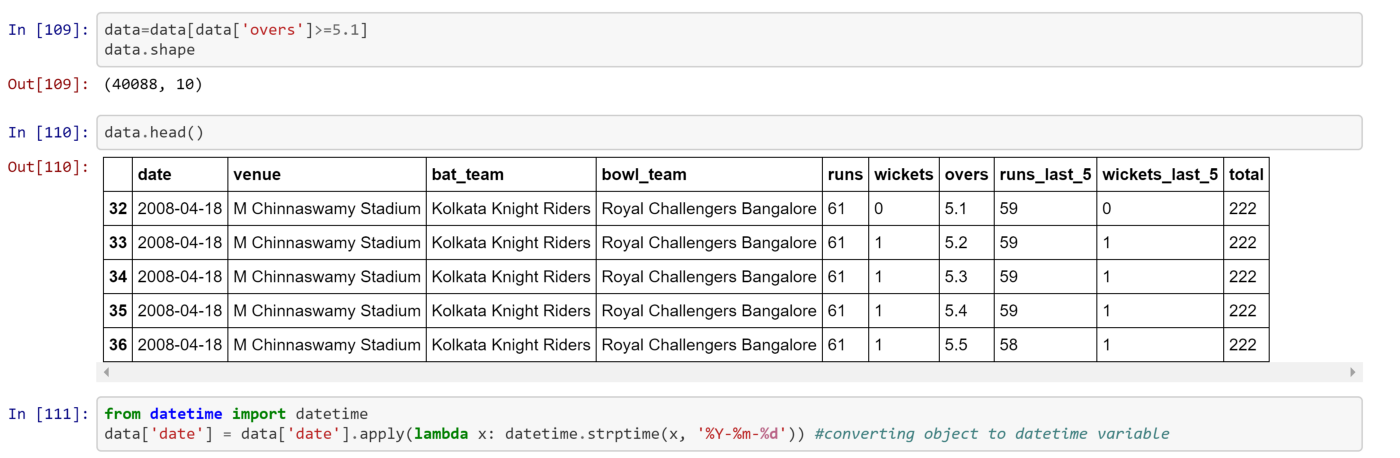
For model to have good generalization, i have set a threshold of 5 overs i.e to include those data in which over is greater than or equal to 5.1 overs. Doing so, our model will be able to predict a relevant score when team have at least played 5 overs. Also, i have converted date column from object variable type to date-time variable.
We have three categorical features in our data set(venue, bat_team, bowl_team). I have applied one-hot encoding to those feature using pandas library. Finally, our data preprocessing task is completed.
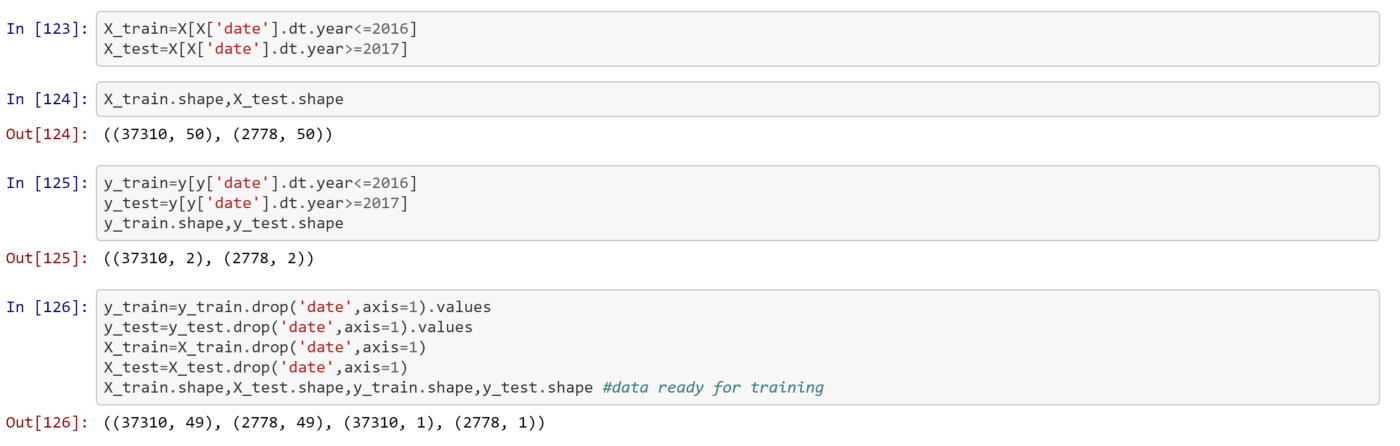
Now, let us divide our data to training and testing set. For this we will not use train_test_split. This is because we have time-series data set. So, I have used date column to split the data. The matches from 2008–2016 are kept in training set, and matches of 2017 in test set. After splitting the data set, i have dropped date column as there in no correlation between predicting score and date.
For training, i have used linear regression, decision tree and random forest algorithms and calculated r2 score for each. Linear regression gave better r2 score (0.75) than decision tree (0.48) and random forest (0.64).
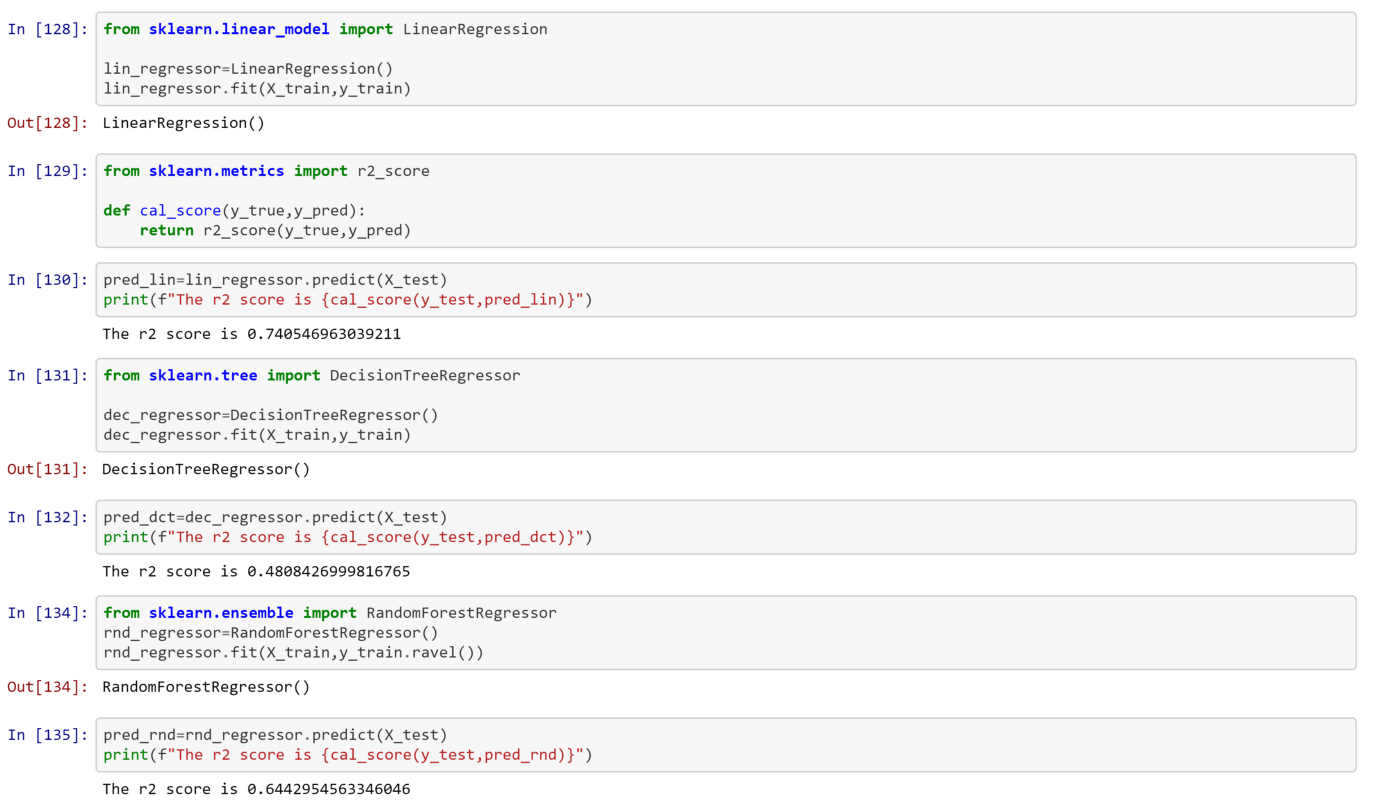
I tried some hyperparameter optimization in Ridge linear regression using RandomizedSearch CV algorithm, but r2 score of this model was pretty much equal to that of linear regression. So, i saved the linear model using pickle library.
Deploying Model:
After model creation task is completed, create a project directory and set up a virtual environment to install flask.
$ python -m venv ipl_pred
$ ./ipl_pred/Scripts/activate
$ pip install Flask
$ touch main.py
Now, lets import some modules from flask library and load our model in main.py file.
from flask import Flask,render_template,url_for,request
import pickle
import numpy as np
model = pickle.load(open('ipl_score_predictor.pkl','rb'))
app = Flask(__name__)
@app.route("/")
def home():
return render_template('home.html')I have rendered a simple html file which has a form where an end user can input the current match statistic for prediction of final score. For one-hot encoded feature, three numpy array are created which has every element zero except for the one that denotes the value which user inputs.
@app.route("/predict",methods=['POST'])
def predict():
batting_team_arr = np.zeros(7)
bowling_team_arr = np.zeros(7)
venue_arr = np.zeros(30)
if request.method == "POST":
batting_team = request.form["batting_team"]
if batting_team == 'Delhi Daredevils':
batting_team_arr[0]=1
elif batting_team == 'Kings XI Punjab':
batting_team_arr[1]=1
elif batting_team == 'Kolkata Knight Riders':
batting_team_arr[2]=1
elif batting_team == 'Mumbai Indians':
batting_team_arr[3]=1
elif batting_team == 'Rajasthan Royals':
batting_team_arr[4]=1
elif batting_team == 'Royal Challengers Bangalore':
batting_team_arr[5]=1
elif batting_team == 'Sunrisers Hyderabad':
batting_team_arr[6]=1
bowling_team=request.form["bowling_team"]
if bowling_team == 'Delhi Daredevils':
bowling_team_arr[0]=1
elif bowling_team == 'Kings XI Punjab':
bowling_team_arr[1]=1
elif bowling_team == 'Kolkata Knight Riders':
bowling_team_arr[2]=1The input values array are concatenated to form a single array which is then fed to the model for prediction. The result is passed to predict.html file which displays the prediction of the match score.
runs = np.array([int(request.form['runs'])])
wickets = np.array([int(request.form['wickets'])])
overs = np.array([float(request.form['overs'])])
runs_in_5 = np.array([int(request.form['runs_in_prev_5'])])
wickets_in_5 = np.array([int(request.form['wickets_in_prev_5'])])
data = np.concatenate([runs,wickets,overs,runs_in_5,wickets_in_5,
venue_arr,batting_team_arr,bowling_team_arr])
prediction = int(model.predict([data])[0])
return render_template('predict.html',prediction=prediction,team=batting_team)I hope I was able to give a proper insight about ML model deployment in flask. You can visit my github repository for template and static files.

Comments