
How Computer Understand Images?
The buzz of “Deep Learning” is significant in the dev-community. It has shown tremendous progress in the field of Computer Vision(CV) and Natural Language Processing(NLP). A lot has been achieved in the recent past years. With the advent of pretrained models and cheaper computation, it’s now as easy as pie to train near state-of-the-art(SOTA) models at home for our most vision and NLP problems. When it comes to images, there are various types of image problems. You can have the standard classification of images in two or more categories to a challenging problem like self-driving cars. The fundamental concept in both of these problems is the same, i.e to understand the images.
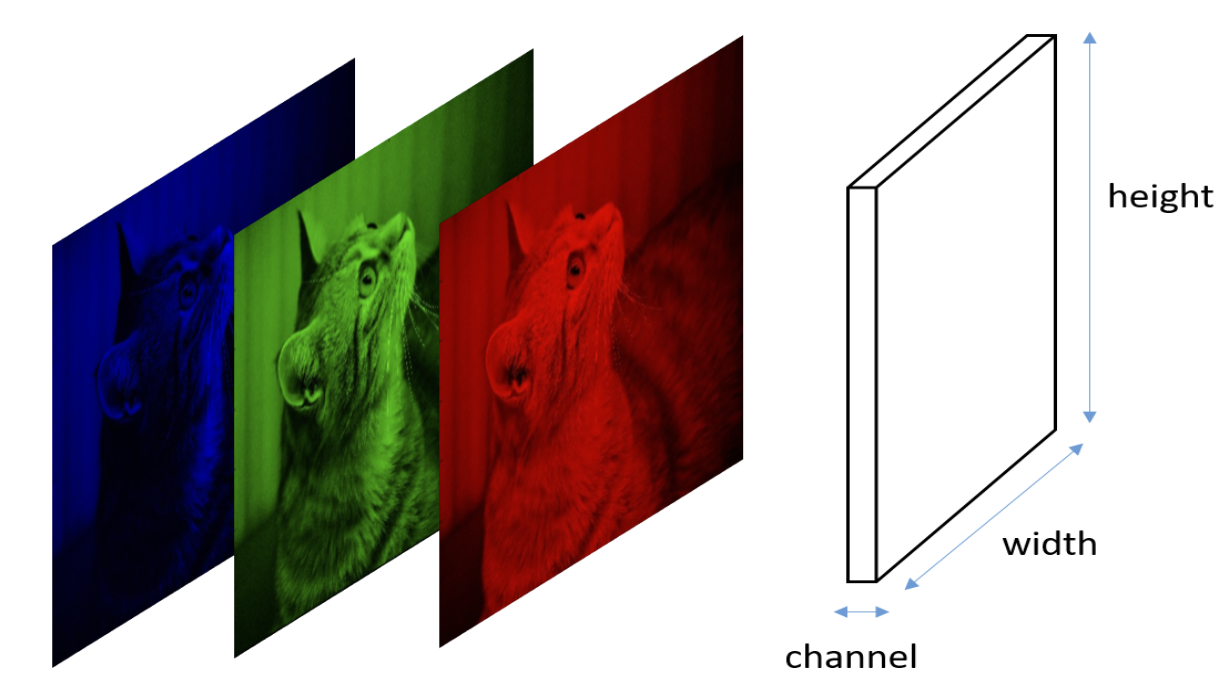
The image that we see is a matrix of numbers(pixels). Unlike us, computers can’t see images, it can only read the numbers and that’s what an image is. A grayscale image is a 2-dimensional matrix in which the number ranges from 0 to 255. 0 is black, 255 is white and in-between are the sheds of grey. On otherside, a color image, usually an RGB, consists of three 2-dimensional matrices having pixel values the same as the grayscale. The three matrices represent the 3-channels of the RGB image.

The traditional approach of solving the image classification problems was to consider every pixel of an image as a feature for the model. So, if a grayscale image was of size 28*28 then the total number of features is 784(28*28). A machine learning(ML) model is then trained on the features with their targets. If a linear model is to be used, the features can be further processed to either normalize or standardize the pixel values. This method was working fine but SOTA was yet to be achieved.
In the 1980s, Yann LeCun, a postdoctoral computer science researcher, introduced Convolutional Neural Network(CNN), a specialized artificial neural network that mimics the human vision system. LeCun had built on the work done by Kunihiko Fukushima, a Japanese scientist who, a few years earlier, had invented the neocognitron, a very basic image recognition neural network. The early version of CNN, called LeNet, could recognize the handwritten digits.
This neural architecture has enabled us to achieve the SOTA results for the vision task. The SOTA CNN models include VGG, ResNet, Inception and many more. These models have been trained on Imagenet dataset (image dataset with over 14 million images). Using the pretrained weights of these models, we now can solve classification problems in a few lines of code.
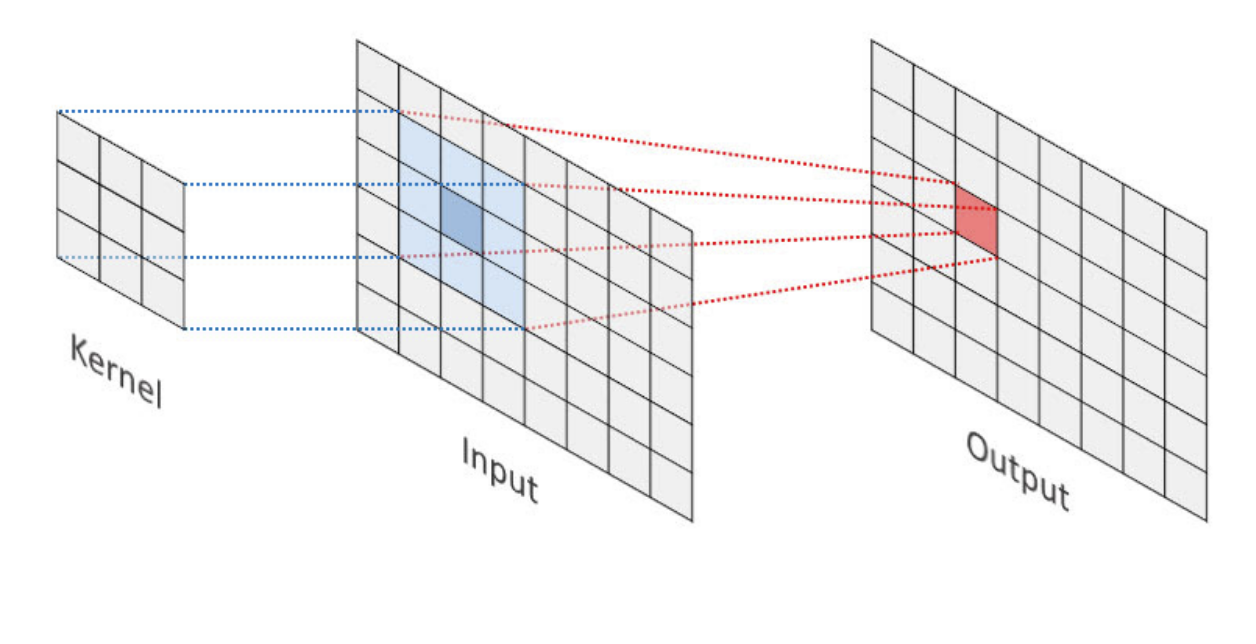
The important part of the CNN architecture is the convolutional layer. In this layer, a kernel/filter of size m*n slides across the pixel values. The value of the kernel and the pixels gets multiplied(element-wise) and summed. As shown in the figure, the kernel’s value gets multiplied with the value in the blue region to obtain the value of the red region. The values obtained get passed through an activation function (usually relu). This is all that happens in the convolutional layer. The image thus achieved is downsampled by passing through a Pooling layer which is similar to the convolutional one. Unlike convolutional, in the Pooling layer the max pixel value inside the blue region is selected.
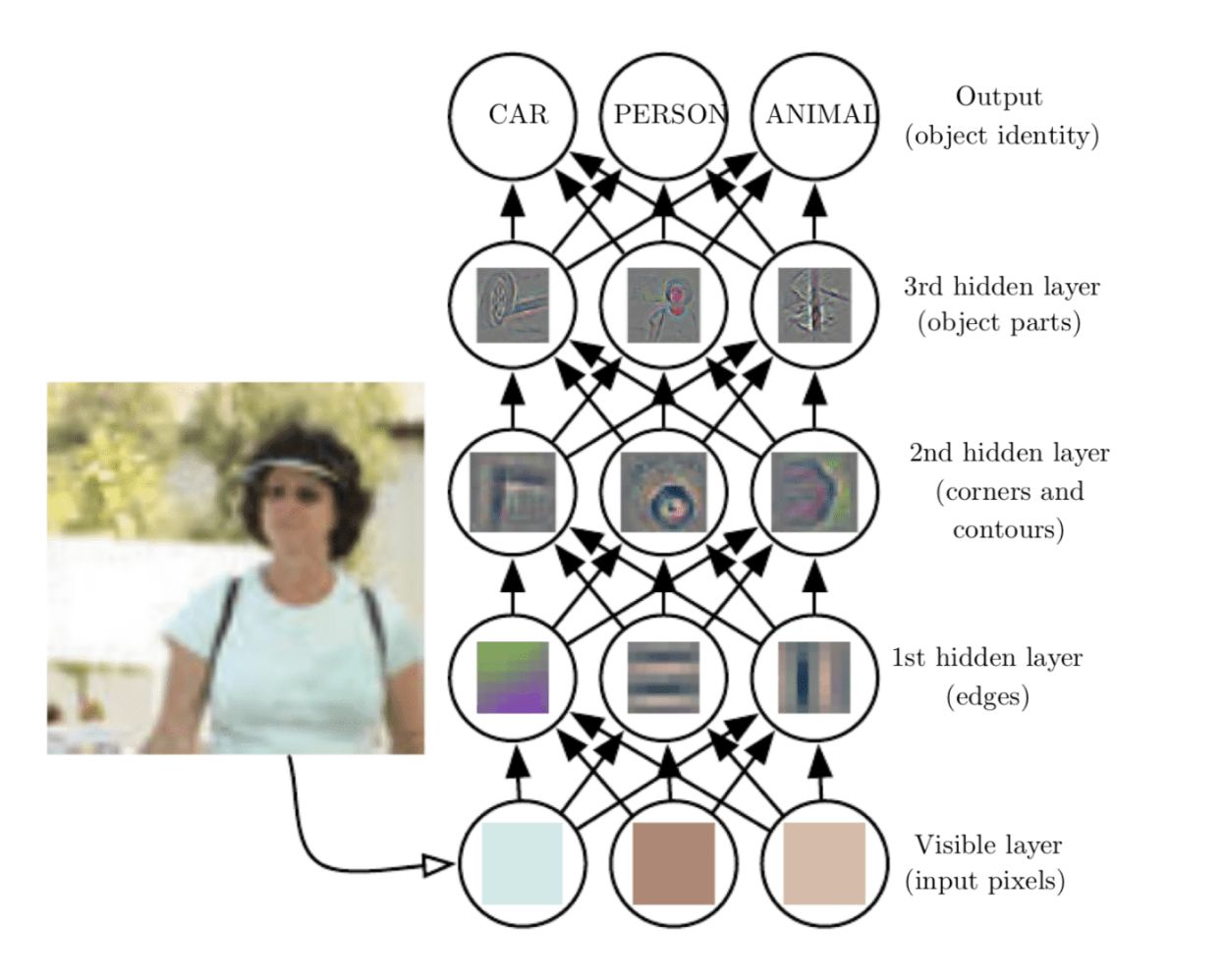
A CNN is usually composed of several convolutional layers and other components. The kernel of the convolutional layers is initialized in such a way that, some layer detects the edges, some detects corners and some detects the object part. The final layer of CNN is a classification layer which takes output of the last convolutional layer. One thing to note, the more the number of convolutional layers, the more complex features the model extracts from the images.
Though CNN is a very powerful and robust architecture, it does have some shortcomings. CNN lacks to capture the context of the images. In one case, a CNN model trained to block inappropriate images in facebook, banned a 30000 years old statue image for nudity. Similarly, CNNs trained on ImageNet and other popular datasets fail to detect objects when they see them under different lighting conditions and from new angles.
Despite the limits of CNNs, however, there’s no denying that they have caused a revolution in artificial intelligence. Today, CNNs are used in many computer vision applications such as facial recognition, image search and editing, augmented reality, and more. In some areas, such as medical image processing, well-trained ConvNets might even outperform human experts at detecting relevant patterns.
With immense research going in the field of CV, new model architecture is proposed that could overcome the shortcomings of CNN. The Transformer is an attention based model architecture that has produced SOTA results in NLP and machine translation. The AI research community is beginning to bring Transformers to the field of computer vision. Facebook recently open-sourced Data-efficient image Transformers(DeiT), a computer vision model that leverages transformers. DeiT requires far less data and far less computing resources to produce a high-performance image classification model. The coming years will definitely bring more powerful models that can better capture the context and understand the image well.
References
Approaching Almost any Machine Learning Problem - Abhishek Thakur
https://towardsdatascience.com/understanding-images-with-skimage-python-b94d210afd23
https://bdtechtalks.com/2020/01/06/convolutional-neural-networks-cnn-convnets/
http://www.terra3d.fr/a-convolution-operator-for-point-clouds/

Comments